If you've ever tried to run a 70-billion-parameter model on a laptop, you already know the punchline: the model won't load. You stare at the console, the memory meter pins, and the whole thing dies with an error that may as well say buy more RAM.
The obvious answer is "buy a bigger Mac." A Mac Studio with 192 GB of unified memory can chew through Llama 3.1 70B at 4-bit quantization without breaking a sweat. But the 405B version — the one that actually rivals GPT-class output — needs more than any single Apple Silicon machine can hold. And if you already own two or three decent Macs, it feels wasteful to have them sit idle while you shop for a $7,000 box.
That's the gap EXO is built to close. It's an open-source runtime that pools the memory of multiple devices into a single inference cluster, letting you run models that are too big for any one of them. A Mac Studio plus a MacBook Pro plus the M3 Mac mini on your shelf can collectively run something you couldn't touch with any of them alone.
Here's how it works, what you need, how to set it up, and where the edges are.
What EXO actually does
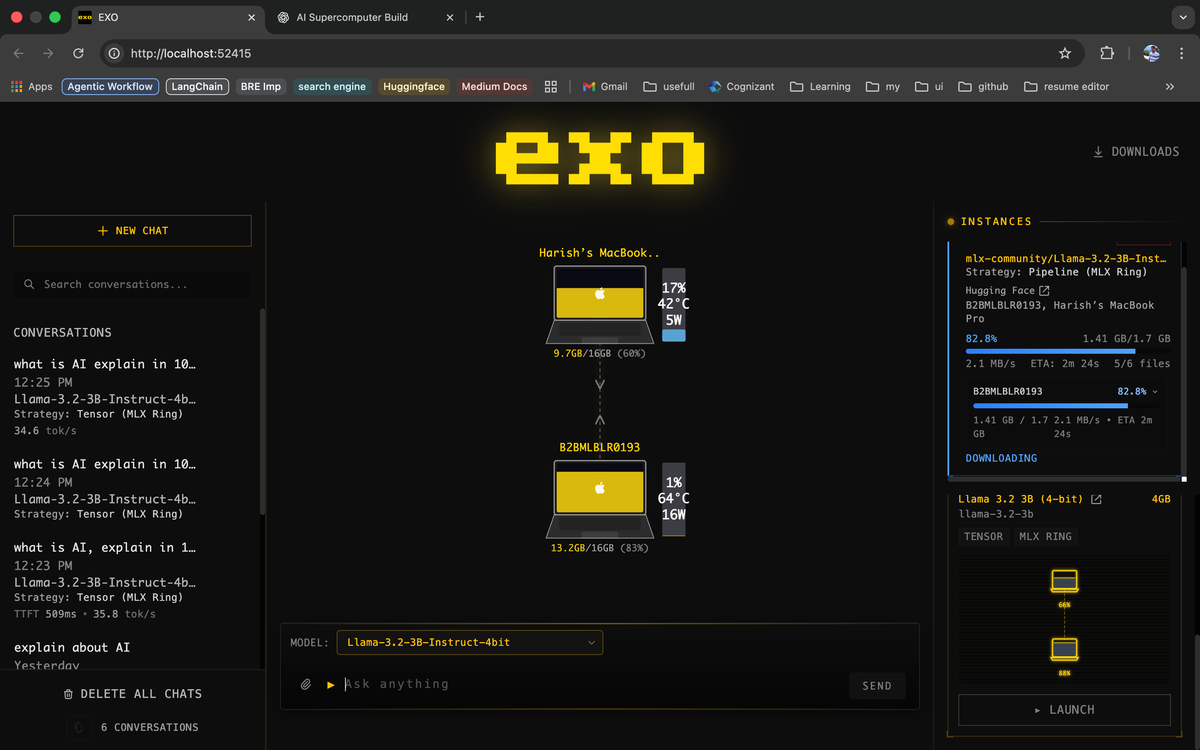
EXO (pronounced "echo") is a distributed-inference project from the exo-explore team. The job it does is straightforward to describe but deceptively hard to pull off well: take a large language model, cut it into pieces along layer boundaries, hand each piece to a different device on your network, and then pass activations between them in the right order to produce tokens.
That pattern is called model sharding, or sometimes pipeline parallelism when every device holds a contiguous stack of layers. EXO uses a variant called ring-based pipeline parallelism — each device holds a slice of the model, and inference moves around the ring in order, with every device doing its part before handing the intermediate state to the next one.
The parts worth knowing:
- Peer-to-peer, no master. There's no coordinator node. Devices discover each other over the local network and negotiate how to split the model.
- Memory-weighted partitioning. A device with 128 GB of RAM gets a bigger slice than one with 16 GB. You don't have to tell it what to do — it works that out from what's available.
- Heterogeneous. Macs, Linux boxes, and (per the EXO docs) iPhones and iPads can all join the same ring. Mixed generations are fine. The slowest or smallest device is always the bottleneck, but it can still contribute.
- MLX on Apple Silicon, tinygrad elsewhere. On Macs, EXO uses Apple's MLX framework, which is the reason unified memory makes this practical in the first place — the GPU and CPU read from the same RAM, no PCIe copy step.
- ChatGPT-compatible API. Once the cluster is up, you hit it like any OpenAI-compatible endpoint. Your app doesn't need to know it's talking to three Macs.
You are not going to beat a single H100 with this setup. What you will do is run a model that a single H100 can't fit, using hardware you already own, without paying for cloud GPU time.
What you need
Three hardware axes matter: total pooled RAM, per-device RAM, and interconnect speed.
Total pooled RAM
This is the simple one. Add up the unified memory of every device you plan to include. Subtract 20–30% for system overhead and context. That's roughly the largest model you can run, given a quantization level.
Rough guide for 4-bit quantized models (community-reported):
| Model | Approx. RAM needed (4-bit) | Fits in |
|---|---|---|
| Llama 3.1 8B | ~6 GB | any Apple Silicon Mac |
| Llama 3.1 70B | ~40 GB | M2 Max 64 GB or pooled across two smaller Macs |
| Mistral Large 2 (123B) | ~70 GB | single Mac Studio 96 GB, or two linked laptops |
| Llama 3.1 405B | ~230 GB | two Mac Studio M2 Ultra 192 GB, pooled |
| DeepSeek-V3 671B | ~380 GB | three M2 Ultra Studios, pooled [verify] |
The 405B figure is where EXO earns its keep — that model is the one that is out of reach for almost every individual buyer, but pooling two Studios puts it in range.
Per-device RAM
This is where people get tripped up. It's not enough for the total to be big — each device also has to hold at least one full transformer block worth of weights, plus activations, plus KV cache, plus OS overhead. A 405B model sharded across three devices roughly means each device holds ~130 GB of weights. An 8 GB MacBook Air can technically join a ring, but there's almost no slice it can meaningfully contribute to for a model this large. Generally you want every device to have at least 16 GB free, and ideally 32 GB, before joining a cluster running a large model.
Interconnect
EXO passes activations between devices at every forward step — hundreds of kilobytes per token, sometimes more. The faster and lower-latency that link is, the better your tokens-per-second.
In practical terms:
- Wi-Fi 6 / 6E works and is the easiest path. Expect slower token rates than a wired setup.
- Ethernet (1 GbE or 10 GbE) is a noticeable upgrade. 10 GbE over Thunderbolt adapters is common in this community.
- Thunderbolt bridge (direct cable between Macs) is the fast path when you only have two devices. It gives you 10+ Gbps with minimal latency and zero router involvement.
If you care about throughput, wire them up. If you're prototyping, Wi-Fi is fine.
Three example configurations
None of these are the "right" setup — pick the one that matches the machines you actually have.
Tier 1 — the laptop fleet. Two or three M-series MacBook Pros (say, a 64 GB M3 Max and a 36 GB M3 Pro). Pooled ~100 GB. Runs 70B comfortably, low-quant 123B with work. Good for the "I already own these" audience.
Tier 2 — studio + laptop. Mac Studio (M2 Max, 96 GB) + MacBook Pro (M3 Max, 64 GB). Pooled ~160 GB. This is the most common real-world EXO cluster people show off. Runs Mistral Large 2 and most 70B–123B models well. [verify: tokens/sec]
Tier 3 — dual Studio. Two Mac Studios with M2 Ultra, 192 GB each. Pooled ~384 GB. The canonical "run Llama 3.1 405B locally" setup. Community reports put this at roughly 1–3 tokens/sec for 405B at 4-bit — slow for interactive chat, acceptable for batch work. [verify: tokens/sec]
Any of these will demonstrate the concept. Tier 1 is where most readers will land.
Installing and running EXO
The install story has moved a couple of times in the past year — pip wheel, Python source, and (recently) a native Mac app are all in the mix. Check the current README at github.com/exo-explore/exo before running these commands; they are accurate as of this writing but the project moves fast. [verify install method]
On each Mac in the cluster
Install Homebrew if you don't have it. Then:
# Python 3.12+ is required
brew install python@3.12
# Clone and install
git clone https://github.com/exo-explore/exo.git
cd exo
pip install -e . --break-system-packagesThat --break-system-packages flag is there because Apple's system Python objects to global installs; if you prefer, use a venv or uv. Either is fine.
First run on a single machine
Before you try to link anything, confirm EXO runs on each machine individually.
exoOn first launch it will download the default model (Llama 3.2 3B as of the last release I checked [verify]) and spin up a local HTTP endpoint on http://localhost:52415. Open that URL in a browser and you will land on a simple ChatGPT-like interface served by EXO itself.
Ask it something. Watch the terminal — you should see token generation and (importantly) a note that it's running a single-node inference. If that works, you're ready to add peers.
Linking a second Mac
The magic part: you don't configure anything. Put both machines on the same Wi-Fi network (or connect them over a Thunderbolt bridge / Ethernet), run exo on each, and they find each other.
# On Mac A
exo
# On Mac B (same network)
exoIn each terminal you will see a line like discovered peer: 10.0.0.42 once the handshake happens. From that point, EXO treats them as one cluster. Hit either machine's HTTP endpoint — the work is automatically split.
Running a large model
Now the payoff. To load something that doesn't fit on one device, pass the model name:
exo run llama-3.1-70b(On whichever machine — it doesn't matter. The model is fetched and the layers are distributed across peers based on memory.)
First run will download weights, which takes a while. Subsequent runs load from local cache. Keep both machines awake during inference — a MacBook that sleeps mid-ring will stall the whole cluster.
Performance: what to actually expect
Here's where the reality check lands. Distributed inference is never faster than single-device inference of the same model on sufficient RAM. It's slower. What it buys you is the ability to run the model at all.
Community-reported numbers as of early 2026, 4-bit quantization [verify all of these against your own run]:
- Llama 3.1 8B, single M3 Max 64 GB: 40–60 tok/s. Baseline for comparison.
- Llama 3.1 70B, pooled 2× M3 Max (laptops, Wi-Fi 6): 6–10 tok/s. Usable for chat.
- Llama 3.1 70B, single M2 Ultra 192 GB: 12–18 tok/s. Faster than the pooled version because there is no network hop.
- Llama 3.1 405B, 2× M2 Ultra over 10 GbE: 1–3 tok/s. Not usable for interactive chat, fine for batch generation overnight.
Two takeaways. First: if the model fits on one machine, run it on one machine. Sharding has overhead. Second: the slower the interconnect, the worse the penalty. Wi-Fi 6 at close range works; Wi-Fi from another room will frustrate you.
Common gotchas
- Macs falling asleep mid-inference. Run
caffeinateor change Energy Saver settings for any machine in the ring. Otherwise the whole cluster stalls when one peer naps. - Asymmetric memory splits. If one device has dramatically more RAM than the others, EXO's weighted partition will load it up heavily — and network latency between it and the small peers becomes the bottleneck. Two similarly-sized machines often outperform one big + one small.
- Thermal throttling on laptops. Sustained inference at 60–80% memory pressure will push a MacBook into thermal limits within minutes. Elevate the laptop, run a cooling pad, or plan for shorter sessions.
- Firewall blocking peer discovery. EXO uses mDNS/UDP multicast to find peers. If you're on a corporate network or have Little Snitch rules, peers won't see each other. Run on a home network or a dedicated switch for best results.
- Model weights don't always quantize identically across nodes. If you manually specify a quantization format, every peer has to use the same one. EXO usually handles this, but if a run fails with a shape mismatch error, check that all peers pulled the same model variant.
Who this is for, and when to stop
EXO earns its place in three situations. The first is the obvious one: you want to run a model that is genuinely too big for any single Mac you own, and you have two or more already sitting around. The second is data posture — you want the weights, the prompts, and the outputs to all stay on your own hardware, which rules out any cloud-inference shortcut. The third is curiosity: you want to actually see distributed inference working, and EXO is a clean, readable implementation of the ring-pipeline pattern without the complexity of a production system like vLLM or DeepSpeed.
The inverse is worth being honest about. If the model fits on one machine, run it on one machine — sharding adds latency and buys you nothing. If you need 30+ tokens per second on a large model for interactive chat, no Mac cluster is going to match a single H100 or a decent cloud endpoint; speed is not what this tool is for. And if your available hardware is one capable Mac and a shelf of 8 GB MacBook Airs, the memory math will not work in your favor — every node has to hold enough of the model to be useful, and the smallest node is always the bottleneck.
The sweet spot for most readers here is a two-device setup — two MacBook Pros, or a laptop paired with a Mac Studio — running 70B-class models when the moment calls for more horsepower, and a single machine for everything else. The 405B showcase is the benchmark that gets EXO written about, but for day-to-day work a smaller model at faster speed almost always wins.
Quick checklist to get running this weekend
- Confirm you have at least two Apple Silicon Macs with ≥16 GB each.
- Put them on the same Wi-Fi network. If you have the cables, run Ethernet or Thunderbolt bridge.
- Install Python 3.12+ on each.
- Clone and
pip install -e .EXO on each. - Run
exoon each machine. Confirm peer discovery in the terminal. - Run
exo run llama-3.1-70bon one of them. Wait for the download. Ask it something. - Benchmark your real tokens/sec with
timeand a known prompt. Write it down.
The first session will teach you more than any blog post, including this one. EXO rewards poking at it.
Disclosure: no affiliate links in this piece. EXO is open source and I'm not compensated by the project.